![[znalosti]](images/note.png)
ADO.NET ale nemusí pracovat pouze s databázemi na nějakém serveru. Bylo navrhováno současně s XML třídami v prostředí .NET Framework. Také díky tomu je možno data načítat i ve formátu XML nebo data zapisovat jako XML soubory spolu s definičním souborem XSD definujícím schéma dané databáze.
Nástroje ADO.NET byly navrženy tak, aby se oddělil způsob přístupu k datům od manipulace s daty. K první skupině patří .NET Framework data provider obsahující množinu komponent zahrnujících podmnožiny Connection (připojení), Command (množinu příkazů pro vybrání dat), DataReader (načítání dat) a DataAdapter (adaptér pro připojení k databázi). K druhé skupině řadíme mimo jiné objekt DataSet (skládající se z objektů DataTable, DataRow...). Jedná se o objekty uchovávající data načtená z databází. Tyto objekty mohou s daty pracovat stejně jako s daty v databázi. V dalším textu budeme převážně používat objekt typu DataSet.
Prostředí Microsoft Visual Studio .NET 2003 nabízí poměrně jednoduchý způsob, jak vytvořit připojení k databázi a jak vybrat potřebná data.
Přesto oblast ADO.NET je velice obsáhlá a vydala by na samostatný kurz. Proto si osvětlíme hlavně její základy.
Pro to, abychom mohli s databází pracovat, je třeba nejprve vytvořit připojení. V závislosti na používaném serveru vybereme typ připojení. V našem příkladu budeme předpokládat, že používáme Microsoft SQL Server. Proto použijeme typ SqlConnection z jmenného prostoru System.Data.SqlClient.
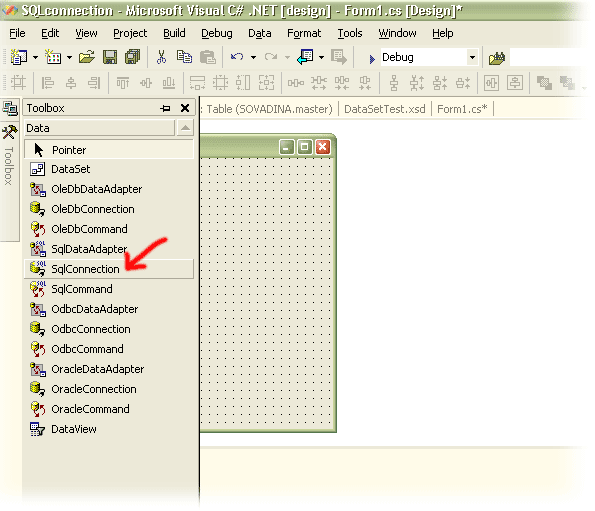
Pro připojení je nutné znát tzv. ConnectionString, tedy řetězec používaný pro připojení k databázovému serveru, ve kterém se uvádí název databáze, login, heslo a další parametry. Naštěstí ve Visual Studiu toto nemusíme nutně znát. Stačí, když, při zobrazení designer (View -> Designer) z Toolboxu (View -> Toolbox - Data) vybereme prostředek s názvem SqlConnection (viz obrázek) a vložíme jej do našeho formuláře.
Tím se vytvoří nový objekt SqlConnection. Zdrojový kód každého vkládaného prvku si můžeme zobrazit poklepáním pravým tlačítkem myši na příslušný prvek a vybráním možnosti View Code. Po vytvoření objektu se vytvoří část kódu
![[ukázka kódu]](images/tip.png) | |
this.sqlConnection = new System.Data.SqlClient.SqlConnection(); | |
kde sqlConnection je jméno instance tak, jak jsme si ji vytvořili.
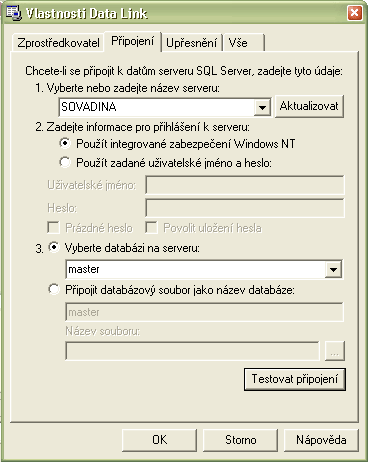
Můžeme vše psát bez pomocí vizuálních prvků. S nimi je ale manipulace daleko jednodušší a přehlednější. Například výše zmíněný ConnectionString nemusíme vůbec vymýšlet. Pravým tlačítkem myši si vyvoláme vlastnosti prvku SqlConnection, kde se v sekci Data nachází rolldown menu pro ConnectionString. Pokud klikneme na nové spojení, objeví se dialogové okno, ve kterém si nastavíme vše, co potřebujeme (viz obrázek).
Samozřejmě na našem serveru (nebo na tom, na který se připojujeme) musí existovat nějaká databáze, ze které budeme data čerpat.
Konkrétně na našem obrázku jsme vybrali databázový server SOVADINA, jméno databáze master. Následně se v metodě InitializeComponent() vytvořil tento ConnectionString:
| |
this.sqlConnection.ConnectionString = "workstation id=SOVADINA;packet size=4096;integrated " + "security=SSPI;data source=SOVADINA;persist security info=False;initial catalog=master"; | |
V ConnectionStringu výraz integrated security=SSPI znamená, že se bude jako login brát přihlašovací jméno do systému (Windows).
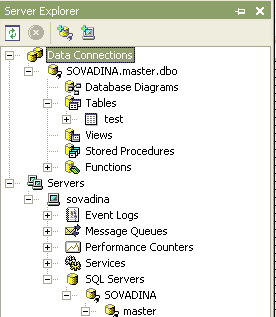
Poté, co jsme vytvořili připojení (SqlConnection), se v nástrojovém okně Server Explorer vytvoří naše připojení jako nová položka Data Connections. Díky této možnosti nebudeme muset prohledávat celý server a pokaždé stačí si patřičná data najít právě zde.
DataAdapter je užitečný především pro spolupráci s prvky dočasné databázové paměti typu DataSet. Pokud se tedy rozhodneme nepoužít DataSet, například u jednoduchých operací, můžeme s databází spolupracovat přímo bez DataAdapteru.
Ve druhém případě je dalším krokem přidání prvku DataAdapter do našeho projektu.
V našem případě použijeme SqlDataAdapter. Opět jej vložíme z Toolboxu. V momentě vkládání se objeví průvodce konfigurací DataAdapteru. Také jej později můžeme vyvolat poklepáním na prvek pravým tlačítkem myši, volba Configure Data Adapter.
V průvodci Data Adaptéru si opět můžeme vybrat různá nastavení, např. zda dotazy na databázi budeme vytvářet sami nebo chceme opět použít průvodce s předdefinovanými procedurami.
Pokud se po ukončení průvodce podíváme na vlastnosti prvku SqlDataAdapter, zjistíme, že jsou nastaveny vazby na SqlConnection, které jsme vytvořili dříve. Můžeme opět jednotlivé vlastnosti měnit podle našich přání a požadavků. Například měnit dotazy typu SELECT, INSERT, UPDATE, DELETE.
Samozřejmě u zdrojových kódů přibyla spousta nových řádků, které vygenerovalo vývojové prostředí.
Je na místě oznámit, že je třeba vytvořit tolik prvků SqlDataAdapter, do kolika tabulek databáze se budeme chtít připojovat.
Nyní máme vytvořené potřebné připojení k databázi a připravena data vybraná pomocí příkazů pro práci s databázemi. Zbývá jen těmito daty naplnit objekty nabízející se v ADO.NET.
Pokud pracujeme s databázemi, lze využívat jejich dat i bez objektu DataSet. Po vytvoření spojení vytvoříme příkaz, který chceme nad naší databází provést a spustíme jej. Pokud příkaz vrací data z databáze (SELECT...), vytvoříme navíc konstrukce pracující s takto získanými daty.
| |
using System;
using System.Data.SqlClient;
...
SqlConnection myConn = new SqlConnection("..."); // spravny connection string
SqlCommand selectCommand = new SqlCommand("SELECT ... WHERE ... ", myConn); // spravna formulace dotazu SELECT
SqlDataReader myDataReader = new SqlDataReader();
myDataReader = selectCommand.ExecuteReader();
try {
myConn.Open();
while(myDataReader.Read()) {
... // zpracovani dotazu
}
} catch (Exception e) {
Console.WriteLine("Zase se to stalo :-( \n" + e.Message);
} finally {
myConn.Close();
} | |
Pro ty z vás, kteří se s programováním s databázemi setkali, nebude ničím zvláštní (až na jazykové odlišnosti) výše uvedený kód.
Nejprve se vytvoří spojení s databází. Následuje příkaz SELECT. Ten vybere z databáze data na základě určité podmínky (WHERE). DataReader načítá vždy po jednom záznamu vyhovujícímu podmínce. Data takto získaná lze zpřístupnit pomocí indexerů. Pokud například chceme získat všechna data z tabulky test obsahující sloupce IDzakazky, nazev, hodnota, pak myDataReader bude vždy (pokud byl správně vygenerován na počátku) obsahovat indexery myDataReader["IDzakazky"], myDataReader["nazev"], myDataReader["hodnota"].